Come un Supercomputer da 1 PetaFLOP può stare sulla scrivania: Caso studio di Fine-Tuning locale con MSI EdgeXpert
AIoT Solutions

Negli ultimi anni il fine-tuning dei modelli AI di grandi dimensioni è diventato una necessità per aziende, sviluppatori e team di ricerca. Ma c’è un problema: i costi del cloud stanno schizzando alle stelle. Affittare un’istanza con GPU di fascia enterprise (come NVIDIA A100 o H100) può costare dai 30 ai 60 dollari l’ora, arrivando facilmente a migliaia di euro al mese per progetti continuativi.
Per questo motivo sta emergendo un nuovo trend: spostare l’AI dal cloud all’on-premise, utilizzando hardware dedicato capace di gestire modelli avanzati in locale, senza dover dipendere da infrastrutture esterne.
Ed è qui che entra in gioco MSI EdgeXpert, un supercomputer AI ultra-compatto basato su architettura NVIDIA Grace Blackwell GB10, capace di fornire 1 PetaFLOP FP4 in un dispositivo grande meno di un libro.
In questo blog raccontiamo un caso studio reale di fine-tuning in locale con EdgeXpert, i risultati ottenuti e perché questo device può rivoluzionare il modo in cui le aziende sviluppano AI.
Il contesto: perché il fine-tuning locale sta diventando fondamentale
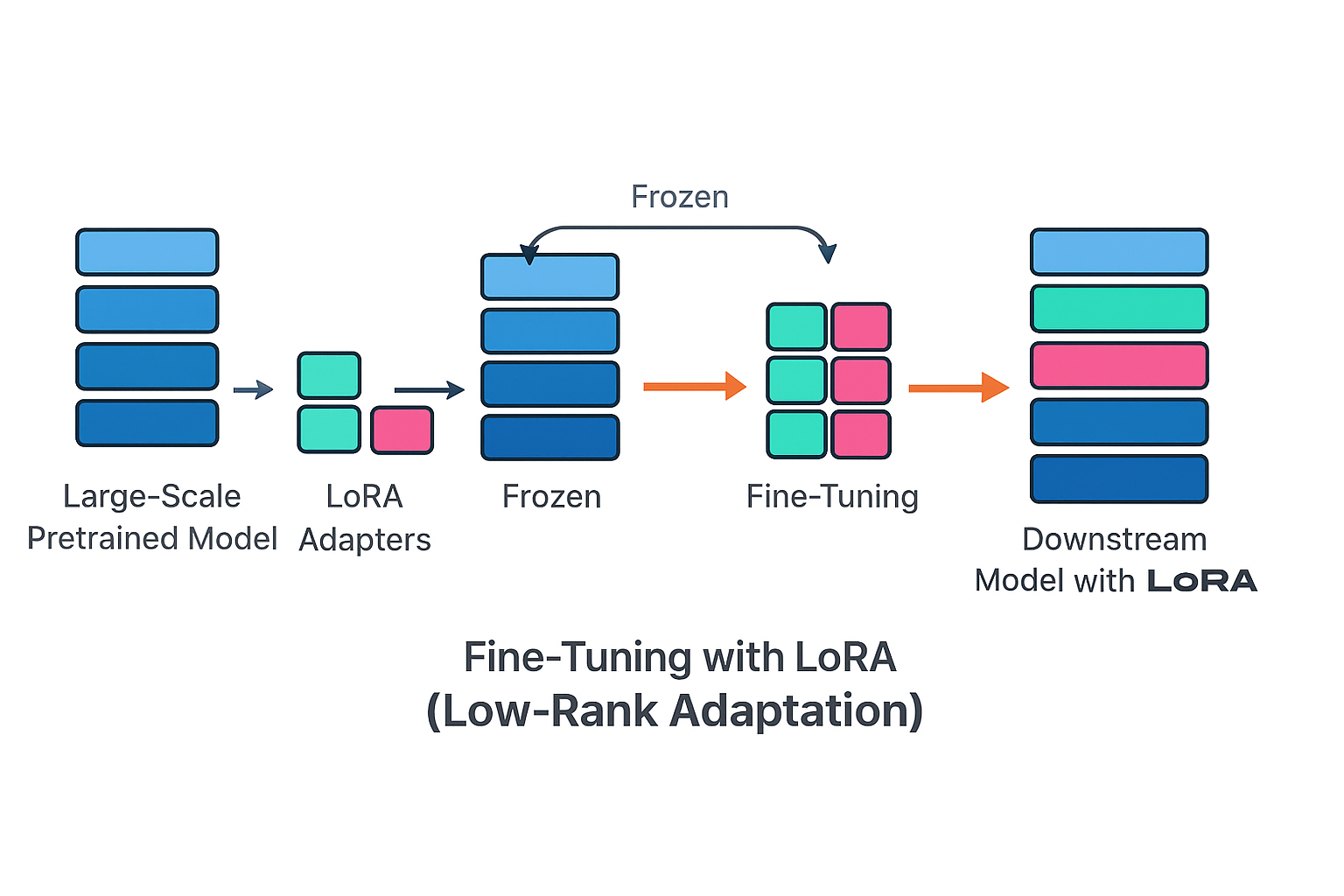
Il fine-tuning di un modello LLM richiede molta memoria (spesso oltre 80 GB), throughput elevato per le operazioni tensoriali, compatibilità con stack software AI complessi e tempi di training che devono restare sotto le 8 ore per iterare velocemente.
Prima di EdgeXpert, eseguire attività come LoRA sul modello Llama 3 8B, il fine-tuning di un VLM 12B con immagini 1024x1024 o anche solo test rapidi su modelli 30-70B era possibile solo con GPU enterprise da data center.
Oggi invece è sufficiente un dispositivo che si appoggia alla NVIDIA DGX Spark Platform, identico nello stack software a quello utilizzato nei centri di calcolo professionali – ma installabile semplicemente sulla scrivania.
Il setup: tutto in locale, senza cloud
Nel caso studio che analizziamo, una software house ha utilizzato EdgeXpert per eseguire un fine-tuning LoRA su un modello Llama 3.1 32B, eseguire prototipi su un modello aziendale proprietario e tracciare metriche via dashboard integrata.
L'operazione è stata gestita interamente in locale, senza cloud esterni, senza licenze aggiuntive e senza necessità di data center o server rack.
Il dispositivo MSI EdgeXpert era configurato con 128GB di memoria unificata LPDDR5X, GPU Blackwell GB10 con architettura NVFP4 e storage NVMe da 4TB.
I risultati: un fine-tuning completo in meno di 8 ore
I benchmark reali mostrano prestazioni sorprendenti: la LoRA sul modello Llama 3.1 32B ha utilizzato 78.7GB di memoria, è durata circa 75 minuti per la fase principale e il throughput è stato elevato e costante grazie alla memoria unificata.
Il fine-tuning completo dei modelli più piccoli è durato 3-4 minuti, grazie alla memoria unificata e al collegamento CPU-GPU NVLink-C2C.
Infine, la dashboard integrata ha mostrato in tempo reale l'utilizzo della VRAM, della CPU e della GPU, oltre a dati utili come learning rate, andamento della loss, saturazione della memoria e velocità di elaborazione dei token. Una visibilità rara anche su molte istanze cloud.
Il dato che fa davvero la differenza: un costo di fine-tuning sotto 1 dollaro
Sul cloud, il fine-tuning dello stesso modello costa circa 30-60$/h su Lambda Labs o RunPod, e circa 32$ per singola ora su istanze AWS con A100.
Con EdgeXpert invece si è registrato un risparmio complessivo del 98%. Il consumo elettrico è stato di 500-700W per 8 ore di test, con un costo elettrico medio di 0,50-0,70$: questo significa un recupero sull'investimento hardware in meno di 3 mesi, con nessun limite d'orario, nessun abbonamento e nessun lock-in.
Privacy totale: i dati non lasciano l’azienda
Un elemento centrale emerso dal caso studio riguarda la sicurezza. Il cliente ha potuto lavorare interamente su dataset interni altamente sensibili e su modelli proprietari, mantenendo il controllo completo degli accessi e limitandoli esclusivamente agli sviluppatori autorizzati.
Tutta l’elaborazione è avvenuta in locale, senza che alcun dato venisse inviato al cloud. Questo approccio elimina alla radice i rischi di data leakage, semplifica la conformità GDPR e protegge totalmente la proprietà intellettuale, offrendo un livello di sicurezza difficilmente raggiungibile con soluzioni AI completamente cloud-based.
Perché EdgeXpert funziona così bene? (in parole semplici)

MSI EdgeXpert presente a Computex 2025
Il motivo per cui EdgeXpert offre prestazioni così elevate è da ricercare nella combinazione di diverse tecnologie chiave. La potenza di calcolo raggiunge livelli da vero e proprio data center grazie al supporto di 1 PetaFLOP in FP4, reso possibile dall’architettura NVIDIA GB10, la stessa che caratterizza i nodi DGX professionali ma in formato ultra-compatto. A questo si aggiungono i 128 GB di memoria unificata, che eliminano i limiti tipici della VRAM tradizionale permettendo a CPU e GPU di condividere la stessa memoria ad alta banda, con notevoli benefici in termini di efficienza e gestione dei modelli di grandi dimensioni.
EdgeXpert eredita inoltre l’intero stack software NVIDIA, identico a quello disponibile sul cloud: NeMo, NIM, NGC, CUDA, ComfyUI e tutti i principali framework AI funzionano in modo nativo e senza alcuna incompatibilità. Infine, l’interconnessione NVLink-C2C elimina le copie di dati superflue, riduce drasticamente la latenza e accelera l’intero workflow, permettendo di eseguire operazioni complesse in modo estremamente fluido e stabile.
Conclusione: il fine-tuning torna nelle mani degli sviluppatori
Il caso studio dimostra come l’AI on-premise non rappresenti più soltanto un’alternativa al cloud, ma stia diventando la scelta ideale per chi sviluppa modelli interni, punta a ridurre sensibilmente i costi operativi, necessita dei massimi livelli di privacy e sicurezza, deve iterare rapidamente sui propri modelli oppure lavora con dataset e architetture di grandi dimensioni.
Con EdgeXpert, MSI rende il fine-tuning avanzato accessibile anche fuori dai data center, mettendolo nelle mani di realtà molto diverse tra loro: software house, università e centri di ricerca, startup, team aziendali dedicati all’AI e persino creator o sviluppatori indipendenti che desiderano costruire modelli personalizzati in totale autonomia.
Si tratta di una trasformazione significativa, che apre nuove possibilità e permette di lavorare in modo più veloce, più sicuro e con costi notevolmente inferiori rispetto alle soluzioni esclusivamente basate sul cloud.


